
ML for simulation
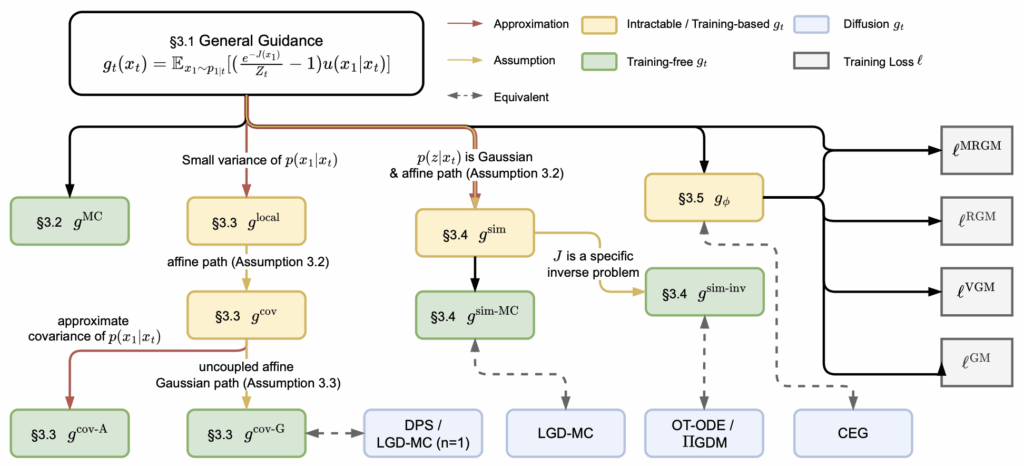
RealPDEBench: A Benchmark for Complex Physical Systems with Real-World Data
Peiyan Hu*, Haodong Feng*, Hongyuan Liu*, Tongtong Yan, Wenhao Deng, Tianrun Gao, Rong Zheng, Haoren Zheng, Chenglei Yu, Chuanrui Wang, Kaiwen Li, Zhi-Ming Ma, Dezhi Zhou, Xingcai Lu, Dixia Fan, Tailin Wu$^†$
ICLR 2026
We introduce the first benchmark for complex physical systems with paired real-world data and simulated data, and explore how to bridge simulated and real-world data.
Generative model
On the guidance of flow matching
Ruiqi Feng, Tailin Wu$^†$, Chenglei Yu, Wenhao Deng, Peiyan Hu
ICML 2025 Spotlight
We introduce the first framework for general flow matching guidance, from which new guidance methods are derived and many classical guidance methods are covered as special cases.
ML for physical control
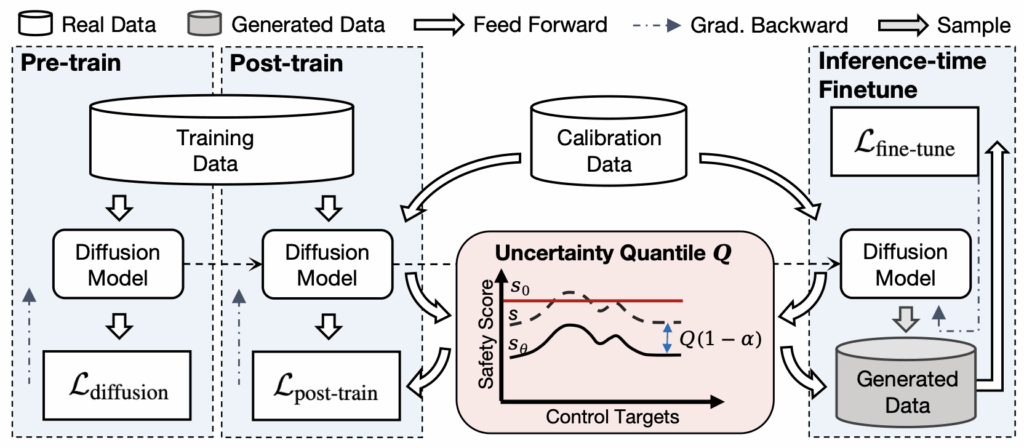
From Uncertain to Safe: Conformal Fine-Tuning of Diffusion Models for Safe PDE Control
Peiyan Hu*, Xiaowei Qian*, Wenhao Deng, Rui Wang, Haodong Feng, Ruiqi Feng, Tao Zhang, Long Wei, Yue Wang, Zhi-Ming Ma, Tailin Wu$^†$
ICML 2025
We propose safe diffusion control with provable guarantee, by using conformal prediction for uncertainty quantification and enforcing safety with posttraining and finetuning.
ML for simulation
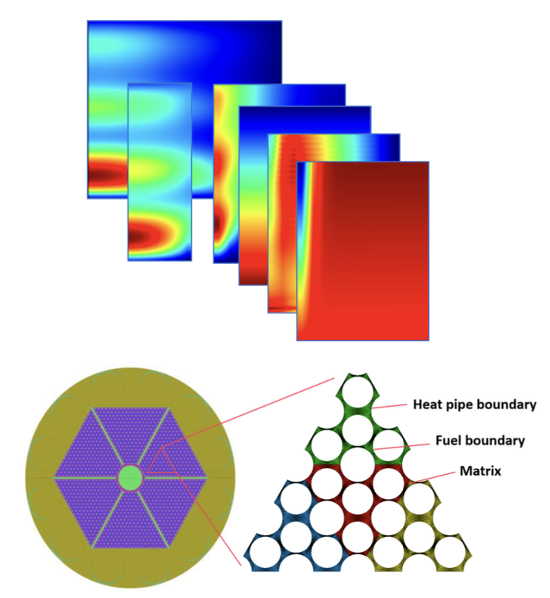
M2PDE: Compositional Generative Multiphysics and Multi-component PDE Simulation
Tao Zhang, Zhenhai Liu, Feipeng Qi, Yongjun Jiao$^†$, Tailin Wu$^†$
ICML 2025
We introduce a diffusion-based approach for multiphysics and multi-component simulations. It can learn from decoupled training data and predict coupled multiphysics and multi-component simulations.
ML for physical control
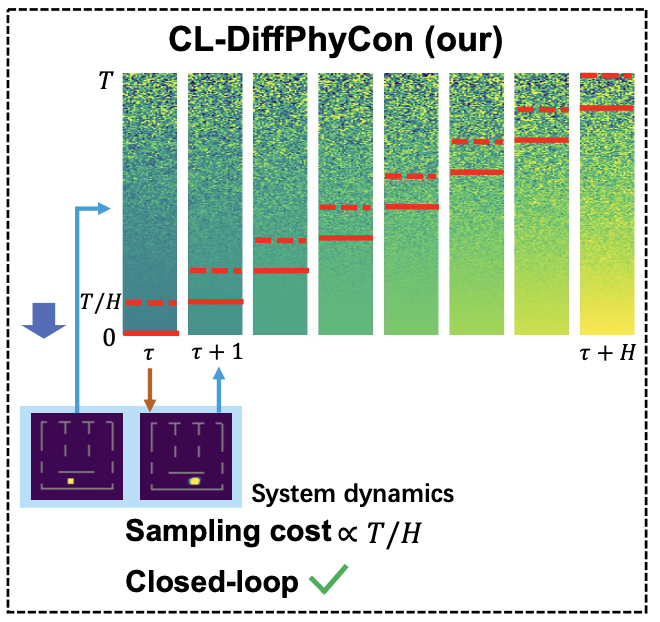
CL-DiffPhyCon: Closed-loop Diffusion Control of Complex Physical Systems
Long Wei*, Haodong Feng*, Yuchen Yang, Ruiqi Feng, Peiyan Hu, Xiang Zheng, Tao Zhang, Dixia Fan, Tailin Wu$^†$
ICLR 2025
Nominated Outstanding Youth Paper Award at China Embodied Al Conference (CEAI 2025)
We propose a diffusion method with an asynchronous denoising schedule for physical systems control tasks. It achieves closed-loop control with significant speedup of sampling efficiency.
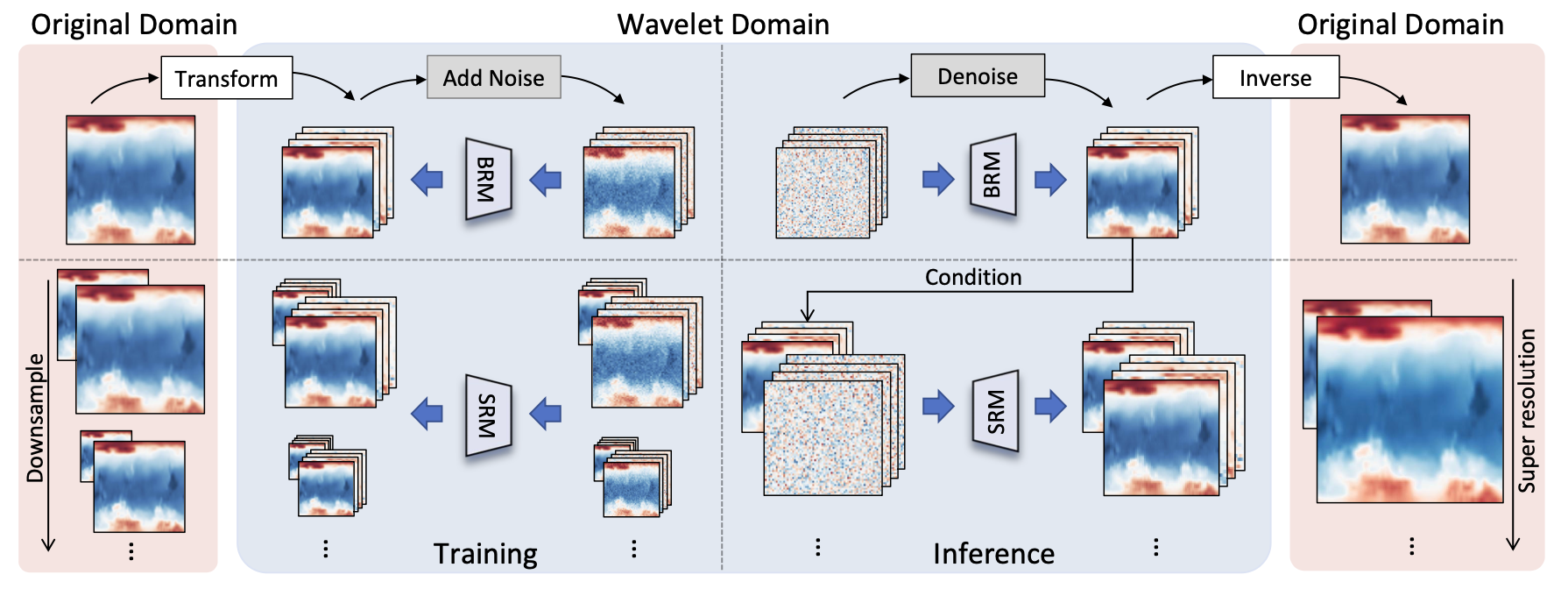
ML for simulation & control
Wavelet Diffusion Neural Operator
Peiyan Hu*, Rui Wang*, Xiang Zheng, Tao Zhang, Haodong Feng, Ruiqi Feng, Long Wei, Yue Wang, Zhi-Ming Ma, Tailin Wu$^†$
ICLR 2025
We propose Wavelet Diffusion Neural Operator (WDNO), a novel method for generative PDE simulation and control, to address diffusion models’ challenges of modeling system states with abrupt changes and generalizing to higher resolutions.
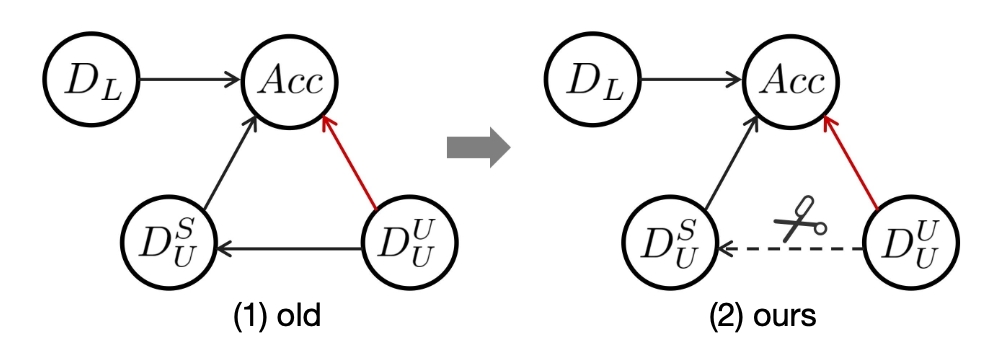
Re-Evaluating the Impact of Unseen-Class Unlabeled Data on Semi-Supervised Learning Model
Rundong He, Yicong Dong, Lan-Zhe Guo, Yilong Yin, Tailin Wu$^†$
ICLR 2025
We re-evaluate the impact of unseen-Class unlabeled data on semi-supervised learning model.
ML for physical control
DiffPhyCon: A Generative Approach to Control Complex Physical Systems
Long Wei*, Peiyan Hu*, Ruiqi Feng*, Haodong Feng, Yixuan Du, Tao Zhang, Rui Wang, Yue Wang, Zhi-Ming Ma, Tailin Wu$^†$
NeurIPS 2024; Oral at ICLR 2024 AI4PDE workshop
We introduce a novel method for controlling complex physical systems using generative models, by minimizing the learned generative energy function and specified objective
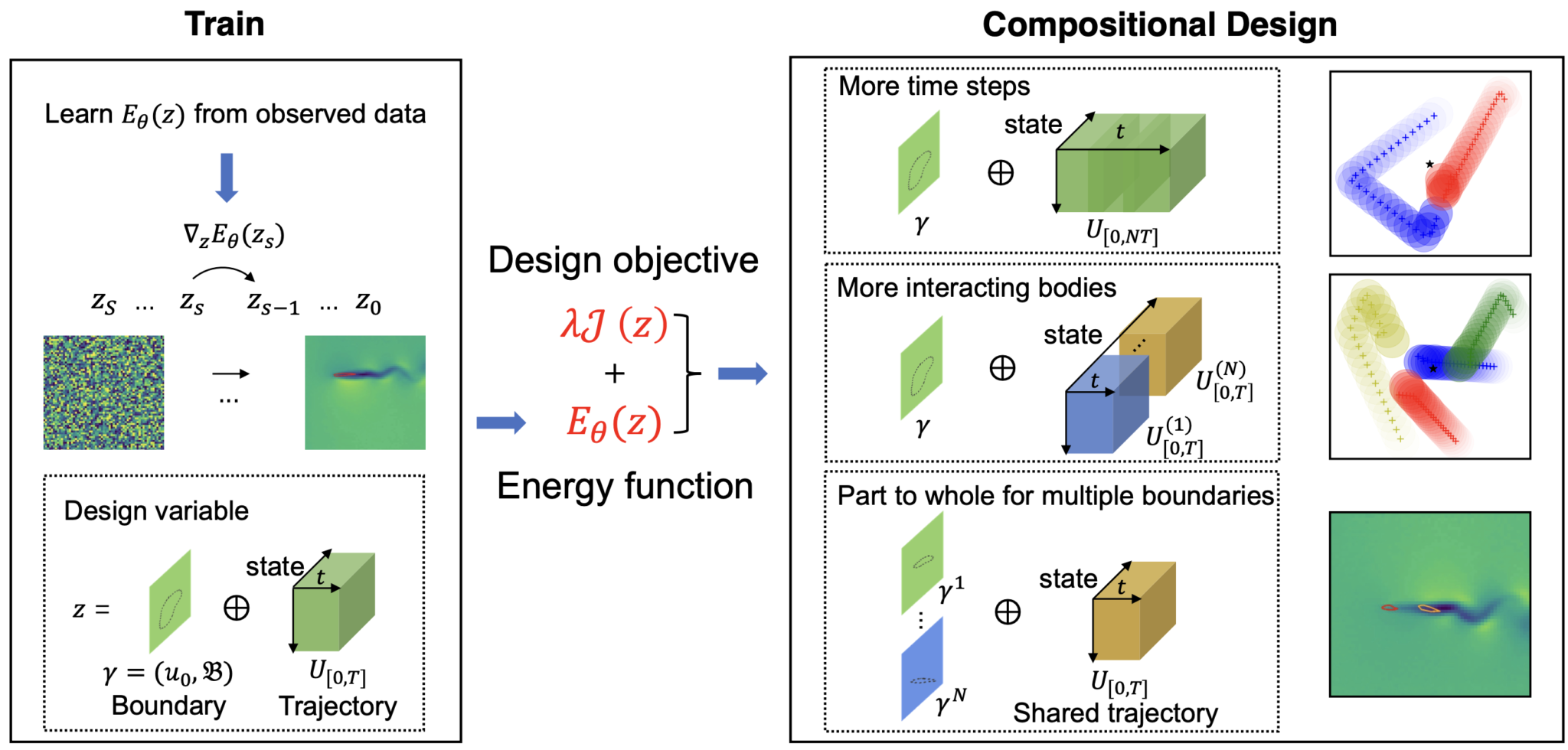
ML for design
Compositional Generative Inverse Design
Tailin Wu*$^†$, Takashi Maruyama*, Long Wei*, Tao Zhang*, Yilun Du*, Gianluca Iaccarino, Jure Leskovec
ICLR 2024 Spotlight
We introduce a method that uses compositional generative models to design boundaries and initial states significantly more complex than the ones seen in training for physical simulations
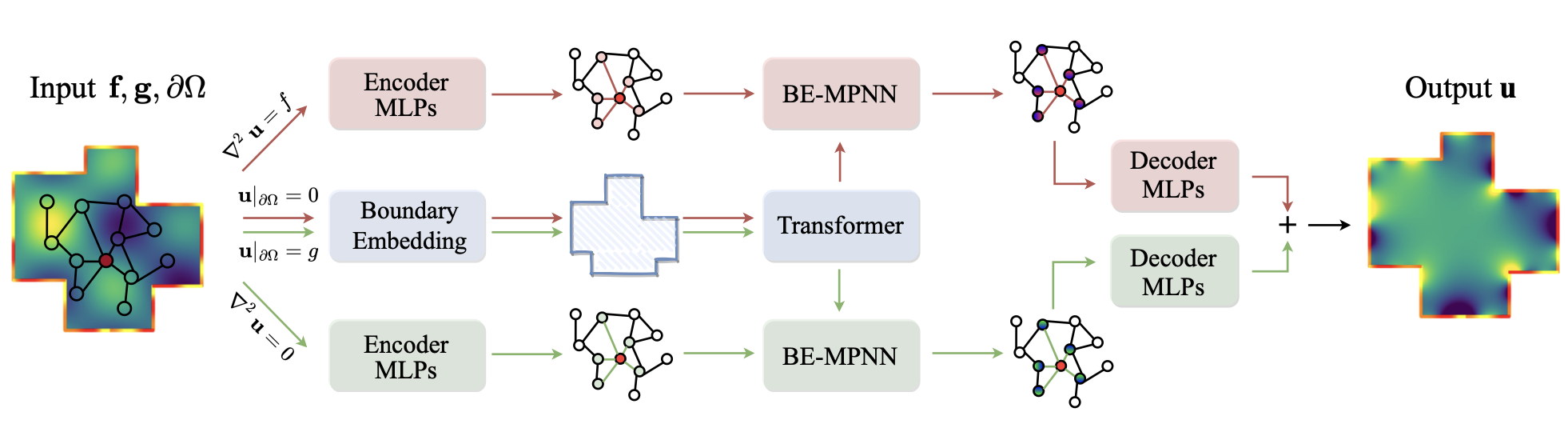
ML for simulation
BENO: Boundary-embedded Neural Operators for Elliptic PDEs
Haixin Wang*, Jiaxin Li*, Anubhav Dwivedi, Kentaro Hara, Tailin Wu$^†$
ICLR 2024
We introduce a boundary-embedded neural operator that incorporates complex boundary shape and inhomogeneous boundary values into the solving of Elliptic PDEs
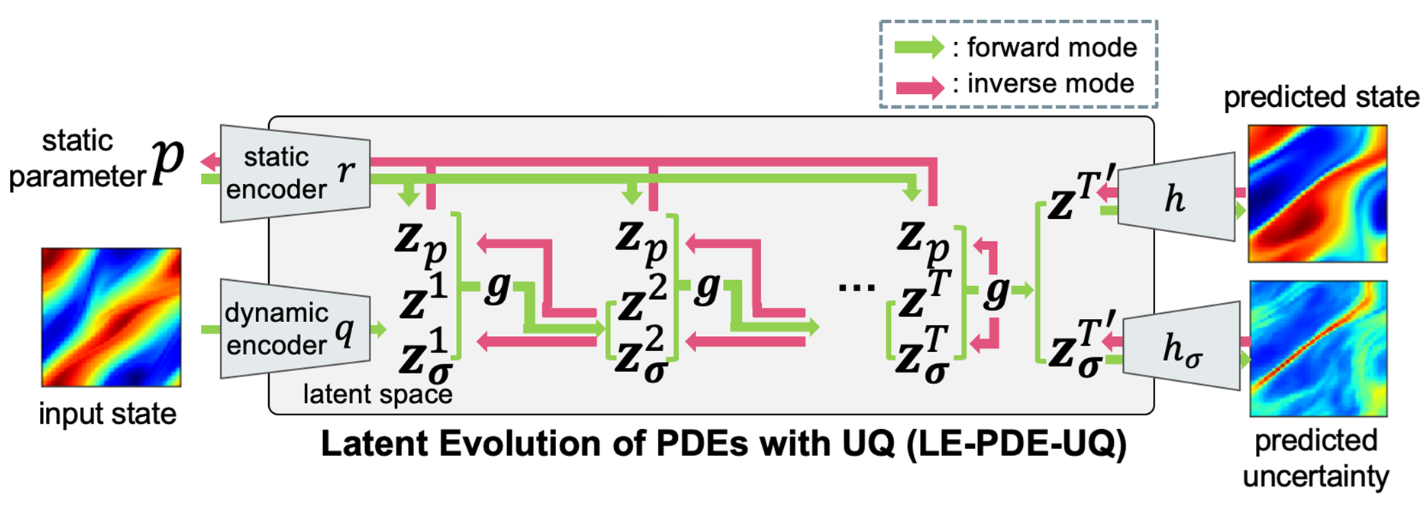
ML for simulation
Uncertainty Quantification for Forward and Inverse Problems of PDEs via Latent Global Evolution
Tailin Wu*, Willie Neiswanger*, Hongtao Zheng*, Stefano Ermon, Jure Leskovec
AAAI 2024 Oral (top 10% of accepted papers)
We introduced uncertainty quantification method for forward simulation and inverse problems of PDEs using latent uncertainty propagation.
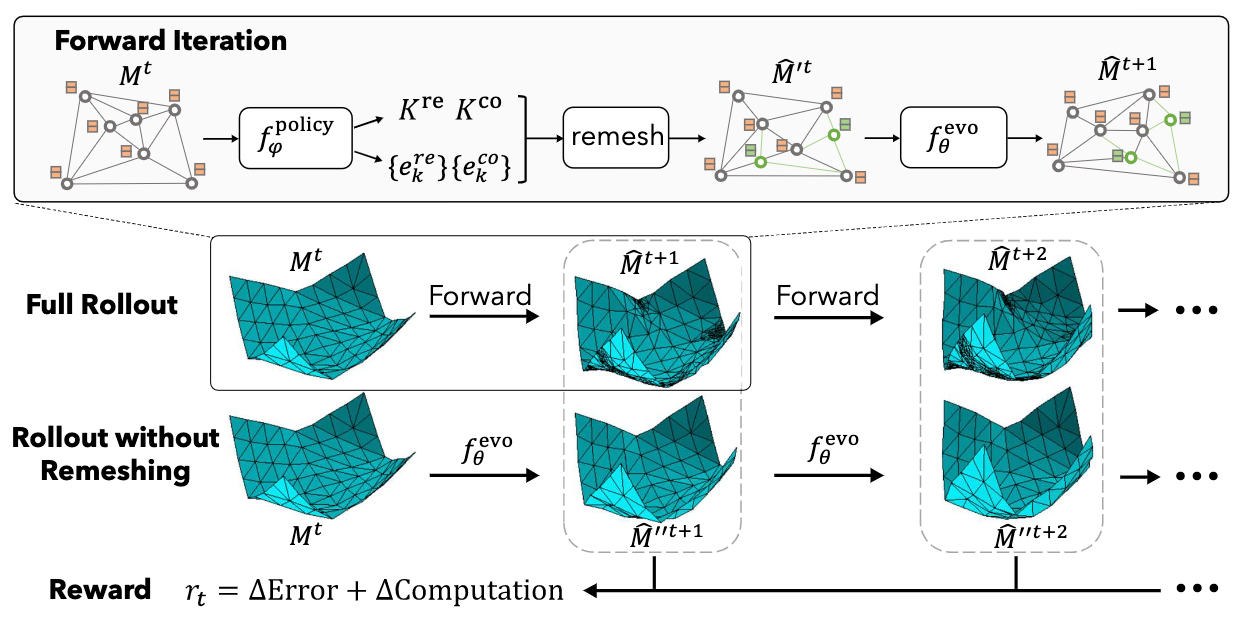
ML for simulation
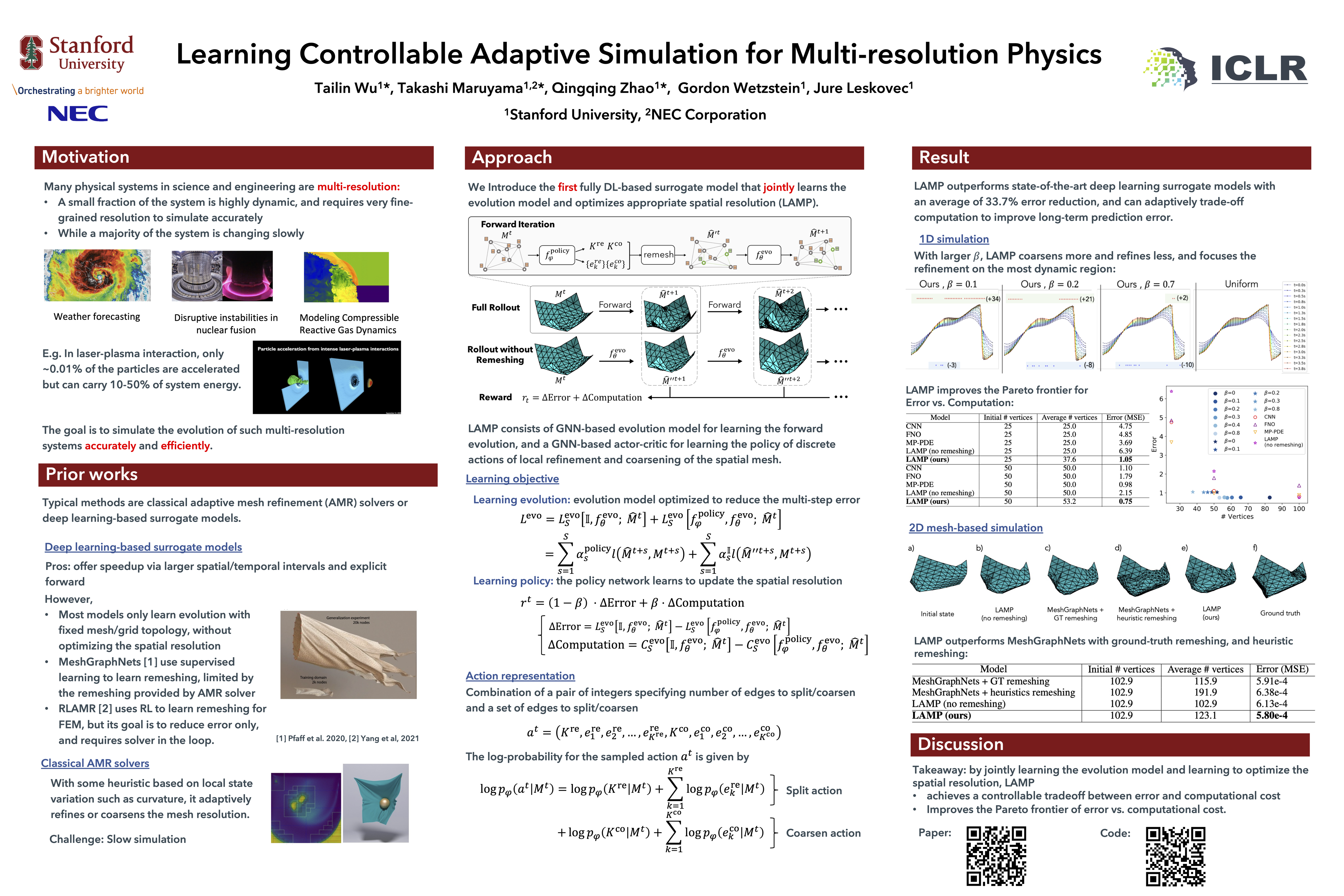
Learning Controllable Adaptive Simulation for Multi-resolution Physics
Tailin Wu* , Takashi Maruyama*, Qingqing Zhao*, Gordon Wetzstein, Jure Leskovec
ICLR 2023 notable top-25%
Best poster award at SUPR
We introduced the first fully deep learning-based surrogate models for physical simulations that jointly learn forward prediction and optimizes computational cost with RL.
ML for simulation
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems
Xuan Zhang, … Tailin Wu (31th/63 author), … Shuiwang Ji
Review paper summarizing the key challenges, current frontiers, and open questions of AI4Science, for quantum, atomistic, and continuum systems.
ML for simulation
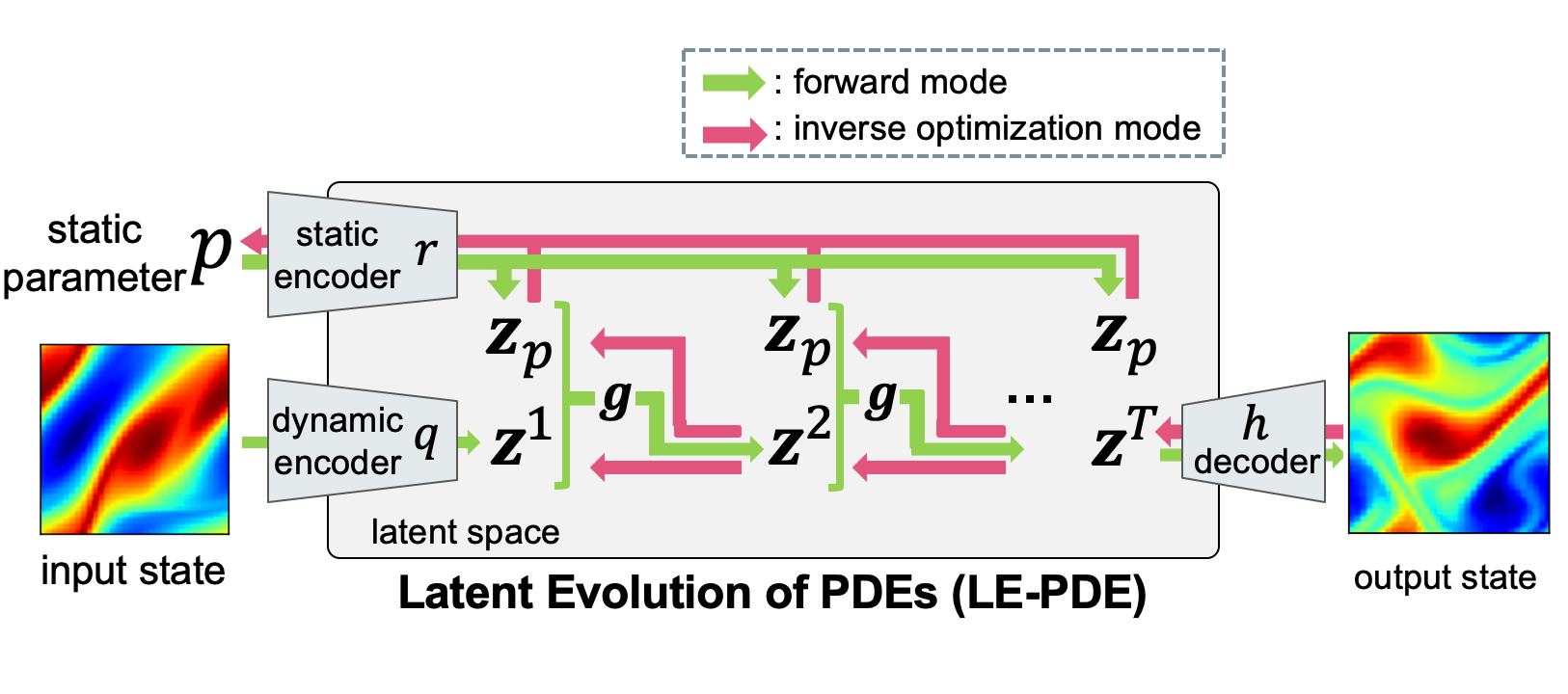
Learning to Accelerate Partial Differential Equations via Latent Global Evolution
Tailin Wu, Takashi Maruyama, Jure Leskovec
NeurIPS 2022
We introduced a method for accelerating forward simulation and inverse optimization of PDEs via latent global evolution, achieving up to 15x speedup while achieving competitive accuracy w.r.t. SOTA models.
ML for simulation
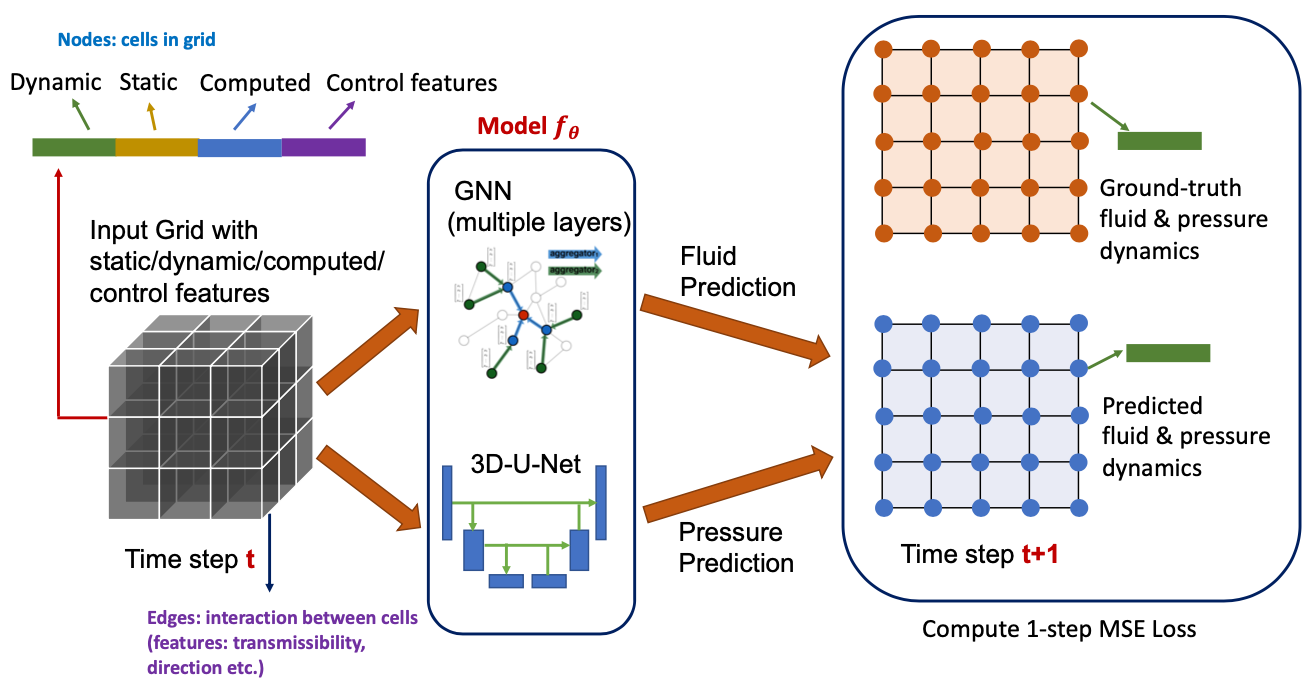
Learning Large-scale Subsurface Simulations with a Hybrid Graph Network Simulator
Tailin Wu, Qinchen Wang, Yinan Zhang, Rex Ying, Kaidi Cao, Rok Sosič, Ridwan Jalali, Hassan Hamam, Marko Maucec, Jure Leskovec
SIGKDD 2022 & ICLR AI for Earth and Space Sciences Workshop long contributed talk
We introduced a hybrid GNN-based surrogate model for large-scale fluid simulation, with up to 18x speedup and scale to over 3D, 10^6 cells per time step (100x higher than prior models).

ML for discovery
ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
Tailin Wu, Megan Tjandrasuwita, Zhengxuan Wu, Xuelin Yang, Kevin Liu, Rok Sosič, Jure Leskovec
NeurIPS 2022
We introduce a neuro-symbolic method that trained with simpler concepts and relations, can zero-shot generalize to more complex, hierarchical concepts, and transfer the knowledge across domains.
ML for simulation
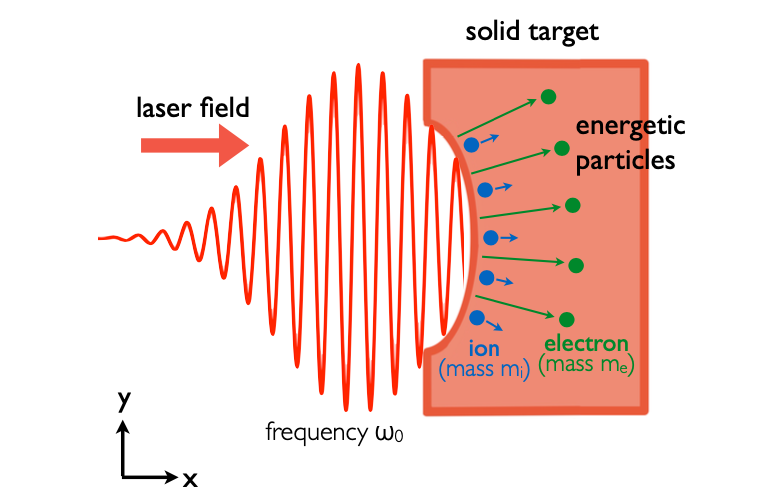
Learning Efficient Hybrid Particle-continuum Representations of Non-equilibrium N-body Systems
Tailin Wu, Michael Sun, H.G. Jason Chou, Pranay Reddy Samala, Sithipont Cholsaipant, Sophia Kivelson, Jacqueline Yau, Zhitao Ying, E. Paulo Alves, Jure Leskovec$^†$, Frederico Fiuza$^†$
NeurIPS 2022 AI4Science workshop, also under review
We introduced a hybrid particle-continuum representation for simulation of multi-scale, non-equilibrium, N-body physical systems, speeding up laser-plasma simulation by 8-fold with 6.8-fold error reduction.
Representation Learning
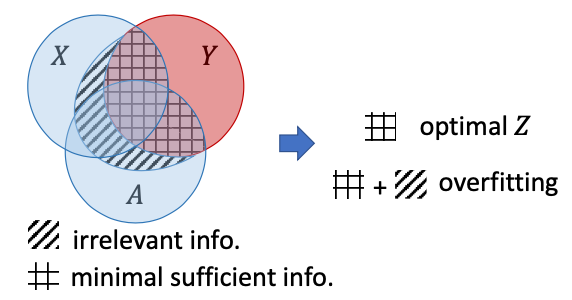
Graph Information Bottleneck
Tailin Wu, Hongyu Ren, Pan Li, Jure Leskovec
NeurIPS 2020
Featured in Synced AI Technology & Industry Review (机器之心)
We introduced Graph Information Bottleneck, a principle and representation learning method for learning minimum sufficient information from graph-structured data, significantly improving GNN’s robustness to adversarial attacks and random noise.
representation learning
Phase transitions for the Information Bottleneck in representation learning
ICLR 2020 We theoretically analyzed the Information Bottleneck objective, to understand and predict observed phase transitions (sudden jumps in accuracy) in the prediction vs. compression tradeoff.

ML for discovery
Toward an Artificial Intelligence Physicist for Unsupervised Learning
Tailin Wu, Max Tegmark
Physical Review E 100 (3), 033311
Featured in MIT Technology Review and Motherboard
Featured in PRE Spotlight on Machine Learning in Physics
We introduced a paradigm and algorithms for learning theories (small, interpretable models together with domain classifier) each specializing in explaining aspects of a dynamical system. It combines four inductive biases from physicists: divide-and-conquer, Occam’s razor with MDL, unification and lifelong learning.
ML for discovery
Discovering Nonlinear Relations with Minimum Predictive Information Regularization
Tailin Wu,Thomas Breuel, Michael Skuhersky, Jan Kautzin
Best Poster Award at ICML 2019 Time Series Workshop
We introduced a method for inferring Granger causal relations for large-scale, nonlinear time series with only observational data.
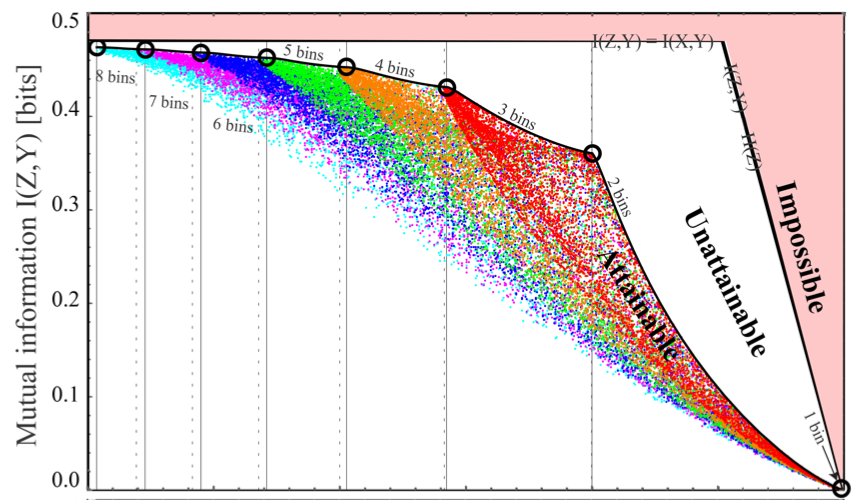
representation learning
Pareto-optimal data compression for binary classification tasks
Entropy 2020, 22(1), 7, as cover issue. arXiv:1908.08961. We introduce an algorithm for discovering the Pareto frontier of compression vs. prediction tradeoff in binary classification of neural networks.
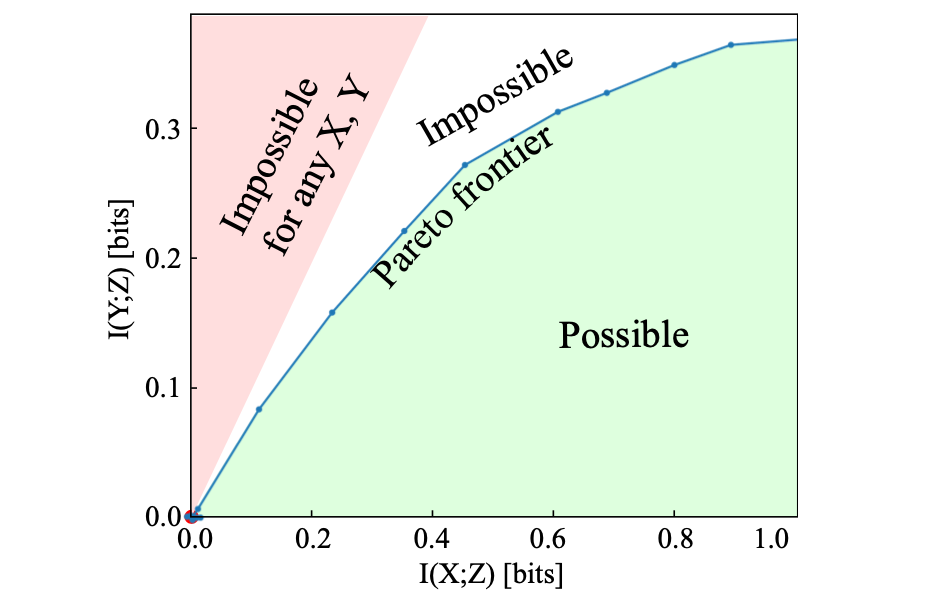
representation learning
Learnability for the Information Bottleneck
Tailin Wu, Ian Fischer, Isaac Chuang, Max Tegmark
UAI 2019, Tel Aviv, Israel
Entropy 21(10), 924 (Extended version)
ICLR 2019 Learning with Limited Data workshop as spotlight
We theoretically derive the condition of learnability in the compression vs. prediction tradeoff in the Information Bottleneck objective.

ML for discovery
AI Feynman 2.0: Pareto-optimal symbolic regression exploiting graph modularity
Silviu-Marian Udrescu, Andrew Tan, Jiahai Feng, Orisvaldo Neto, Tailin Wu, Max Tegmark
NeurIPS 2020, Oral
We introduce a state-of-the-art symbolic regression algorithm that robustly re-discovering top 100 physics equations from noisy data from Feynman lectures.

representation learning
Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels
Curtis G. Northcutt*, Tailin Wu*, Isaac Chuang
UAI 2017 Cleanlab is built on top of it. We introduce a rank pruning method for classification with noisy labels, which provably obtains similar performance as without label noise.
ML for discovery
ViRel: Unsupervised Visual Relations Discovery with Graph-level Analogy
Daniel Zeng*, Tailin Wu*, Jure Leskovec
ICML 2022 Workshop of Beyond Bayes: Paths Towards Universal Reasoning Systems
We introduce a method that discovers common relational structures (analogical reasoning) from few-shot examples.
{kind=link}
ML for discovery
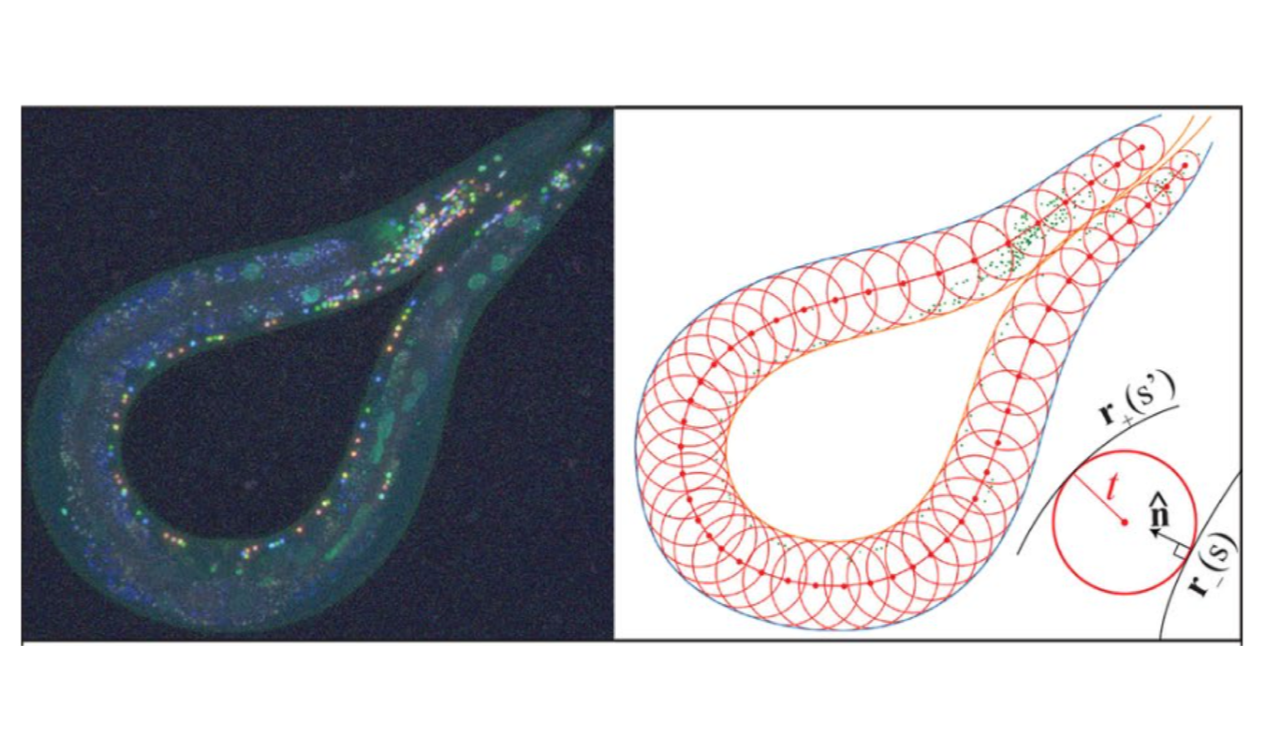
Toward a more accurate 3D atlas of C. elegans neurons
Michael Skuhersky, Tailin Wu, Eviatar Yemini, Amin Nejatbakhsh, Edward Boyden, Max Tegmark
BMC bioinformatics 23 (1), 1-18
We introduce a method for identifying the neuron ID in C. elegans and introduced a more accurate neuron atlas with the NeuroPAL technique.